EasyTune: Efficient Step-Aware Fine-Tuning
for Diffusion-Based Motion Generation
💡 TL;DR: We propose EasyTune, a reinforcement fine-tuning framework for diffusion models that decouples recursive dependencies and enables (1) dense and effective optimization, (2) memory-efficient training, and (3) fine-grained alignment.
📝 Abstract
In recent years, motion generative models have undergone significant advancement, yet pose challenges in aligning with downstream objectives. Recent studies have shown that using differentiable rewards to directly align the preference of diffusion models yields promising results. However, these methods suffer from (1) inefficient and coarse-grained optimization with (2) high memory consumption. In this work, we first theoretically and empirically identify the key reason of these limitations: the recursive dependence between different steps in the denoising trajectory. Inspired by this insight, we propose EasyTune, which fine-tunes diffusion at each denoising step rather than over the entire trajectory. This decouples the recursive dependence, allowing us to perform (1) a dense and fine-grained, and (2) memory-efficient optimization. Furthermore, the scarcity of preference motion pairs restricts the availability of motion reward model training. To this end, we further introduce a Self-refinement Preference Learning (SPL) mechanism that dynamically identifies preference pairs and conducts preference learning. Extensive experiments demonstrate that EasyTune outperforms DRaFT-50 by 7.7% in alignment (MM-Dist) improvement while requiring only 31.16% of its additional memory overhead.
🏗️ Framework
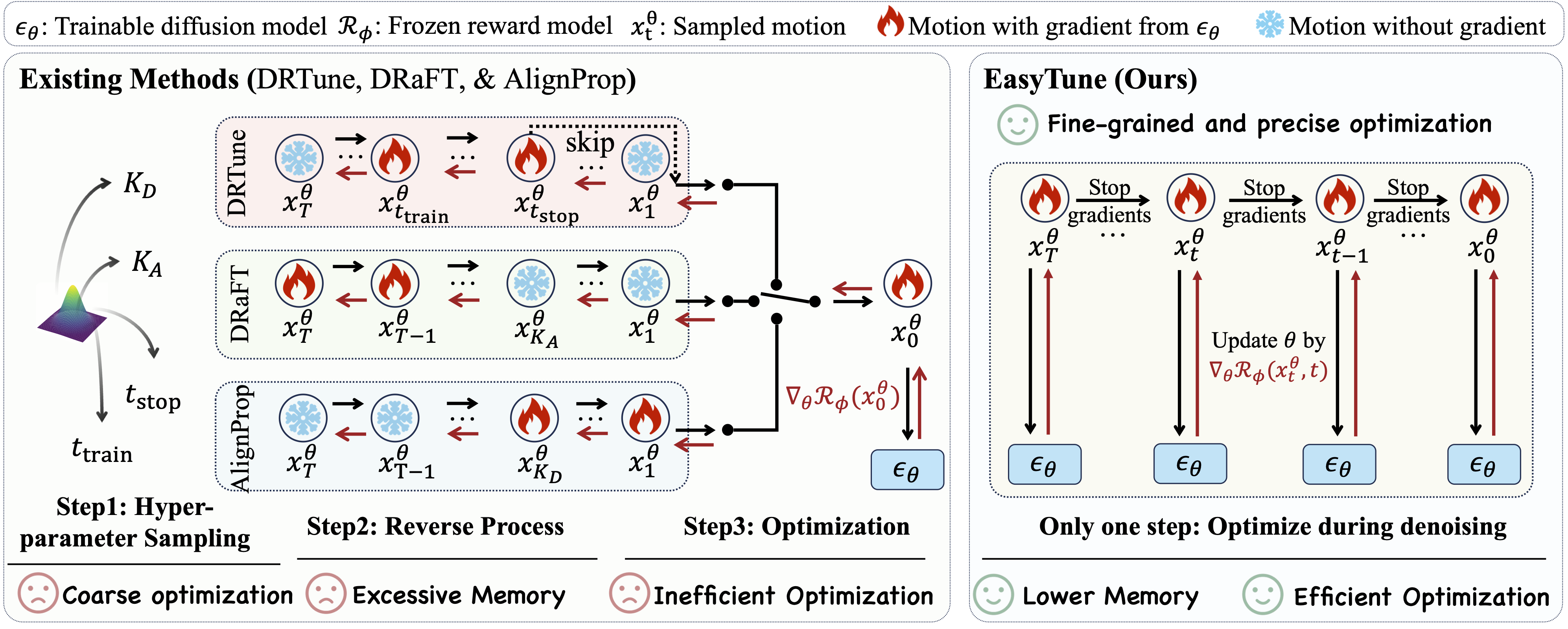
Figure 2. The framework of existing differentiable reward-based methods (left) and our proposed EasyTune (right). Existing methods backpropagate gradients through the overall denoising process, resulting in excessive memory, inefficient, and coarse-grained optimization. EasyTune optimizes by directly backpropagating gradients at each denoising step.
💡 Core Insight
Existing differentiable reward-based methods suffer from inefficient and coarse-grained optimization with high memory consumption. We identify the fundamental reason: the recursive dependence between different steps in the denoising trajectory.
This decouples the recursive dependence, allowing us to perform (1) a dense and fine-grained, and (2) memory-efficient optimization:
- 📦 Step-wise graph storage — Reduced memory footprint
- ⚡ Dense per-step optimization — Faster convergence
- 🎯 Fine-grained parameter optimization — Better alignment
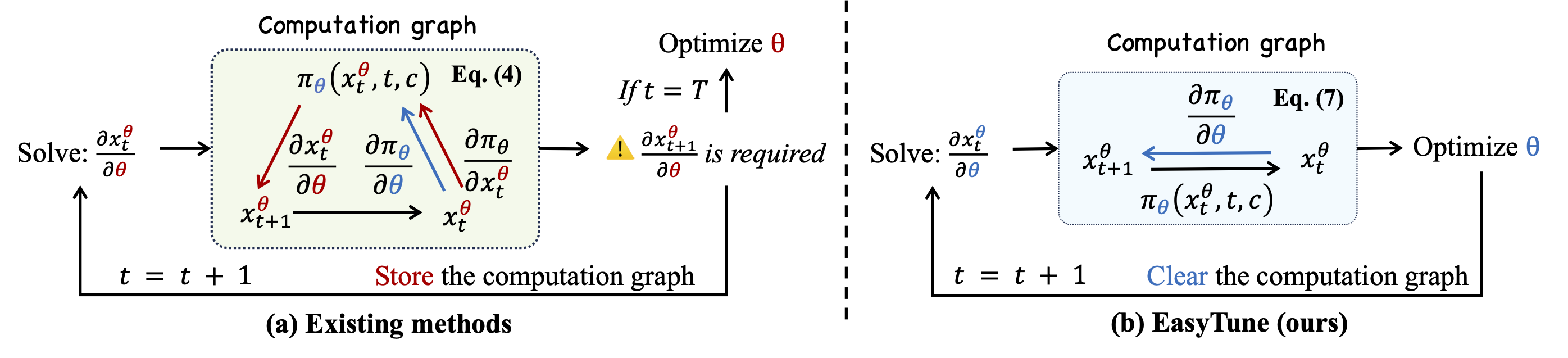
Figure 3. Core insight of EasyTune. By replacing the recursive gradient in Eq.(4) with the formulation in Eq.(7), EasyTune decouples the recursive dependence of computation graph.
📊 Experiments
🏆 Main Results on HumanML3D
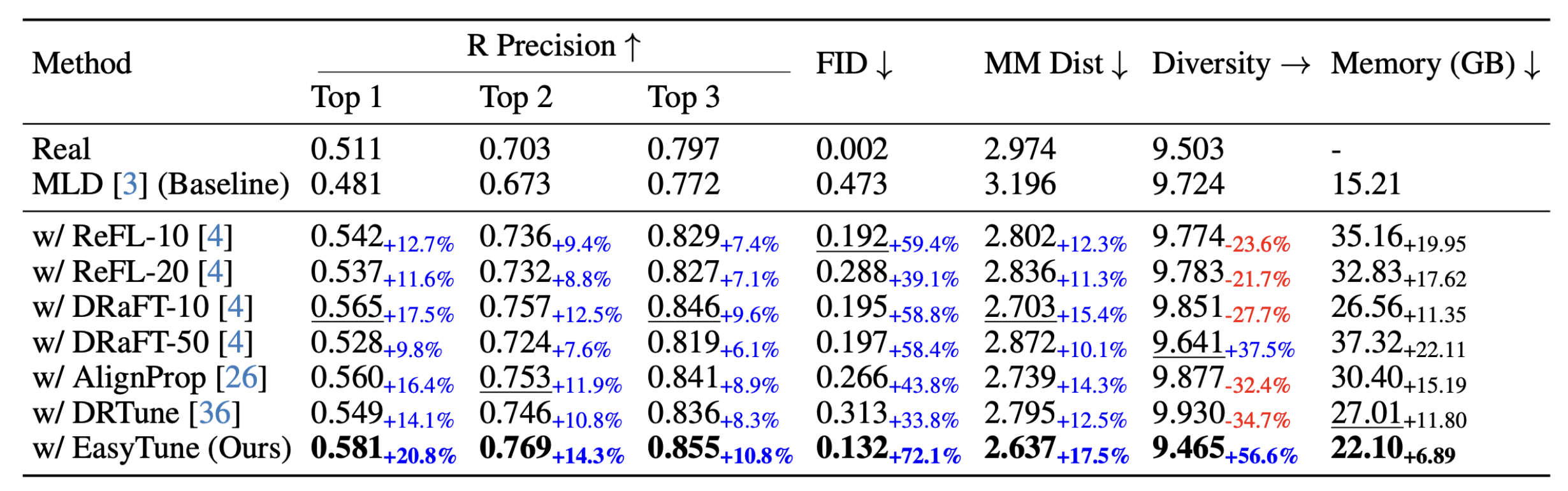
Table 1. Comparison of SoTA fine-tuning methods on HumanML3D dataset. ↑/↓/→ indicate higher/lower/closer-to-real values are better. Bold and underline highlight best and second-best results.
📈 Text-to-Motion Generation
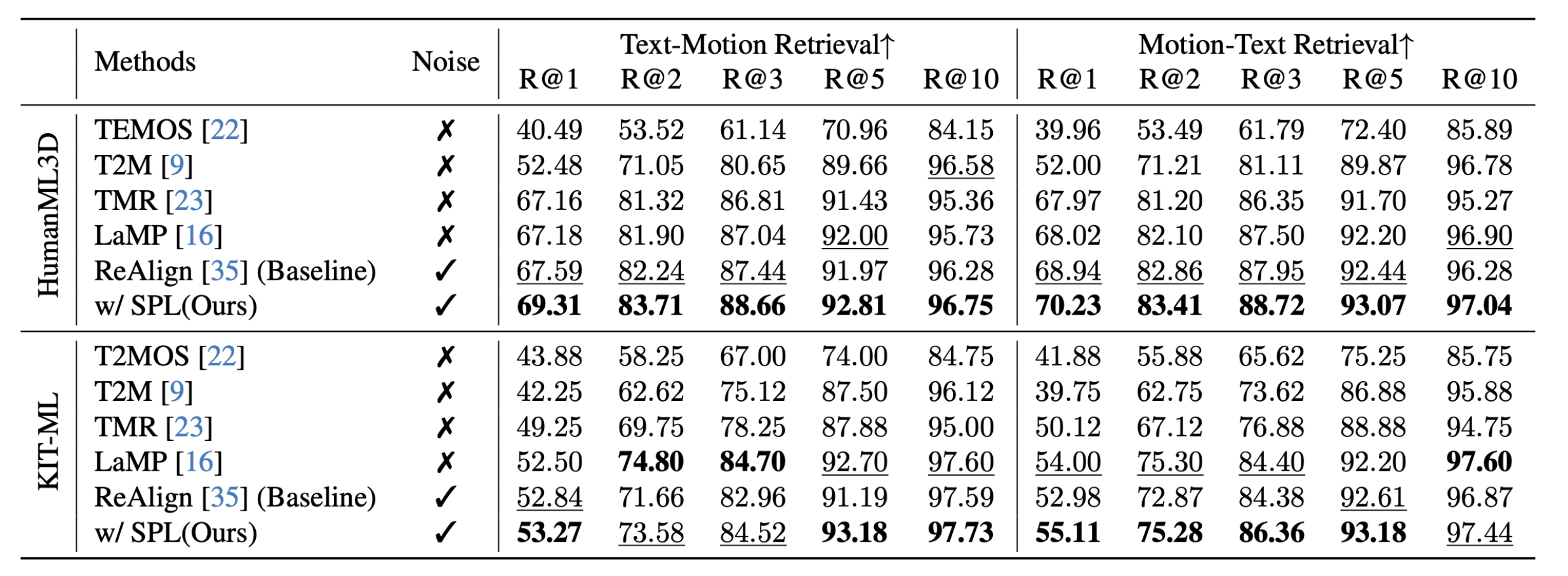
Table 2. Comparison of text-to-motion generation performance on the HumanML3D dataset.
🔬 Text-Motion Retrieval
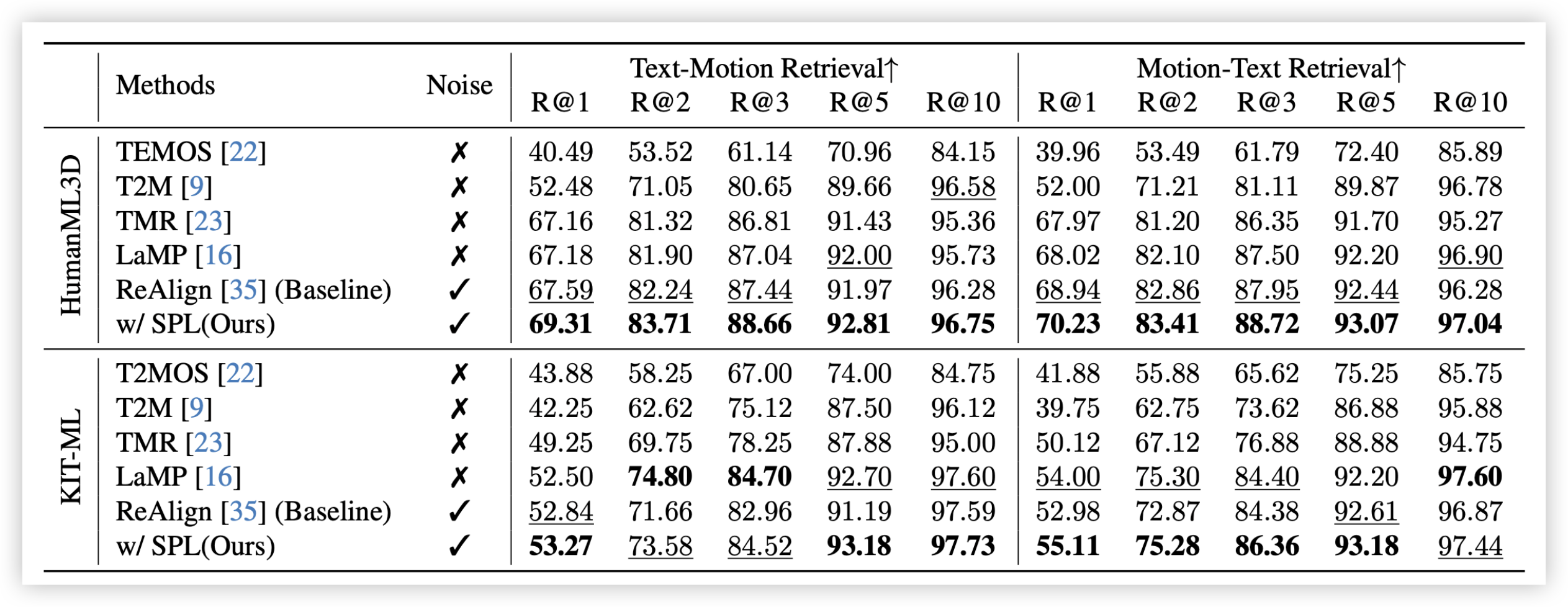
Table 3. Evaluation on Text-Motion Retrieval Benchmark. "Noise" indicates whether the method can handle noisy motion from the denoising process.
🔄 Generalization
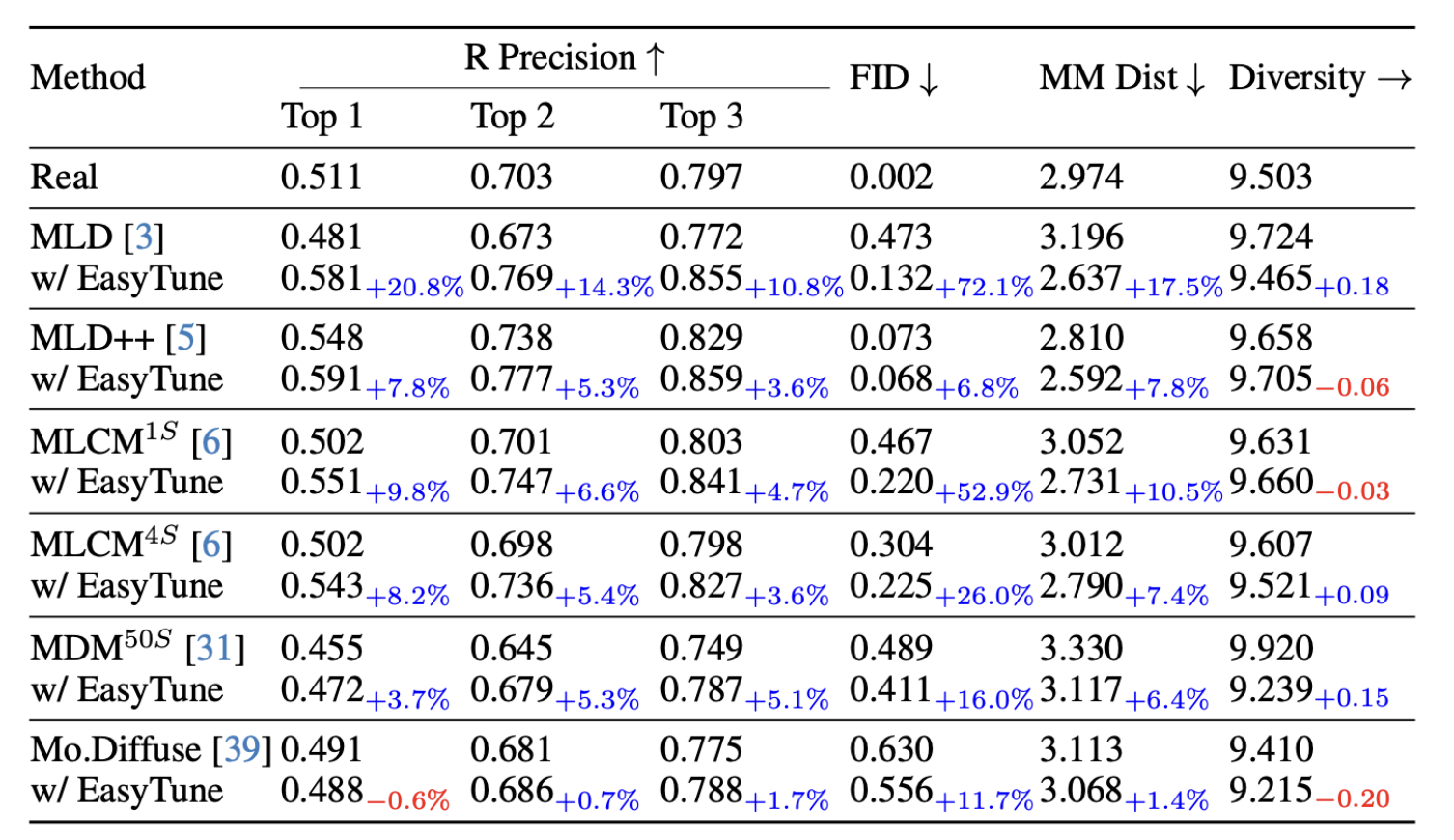
Table 4. Performance enhancement of diffusion-based motion generation methods with EasyTune.
⚡ Computational Overhead
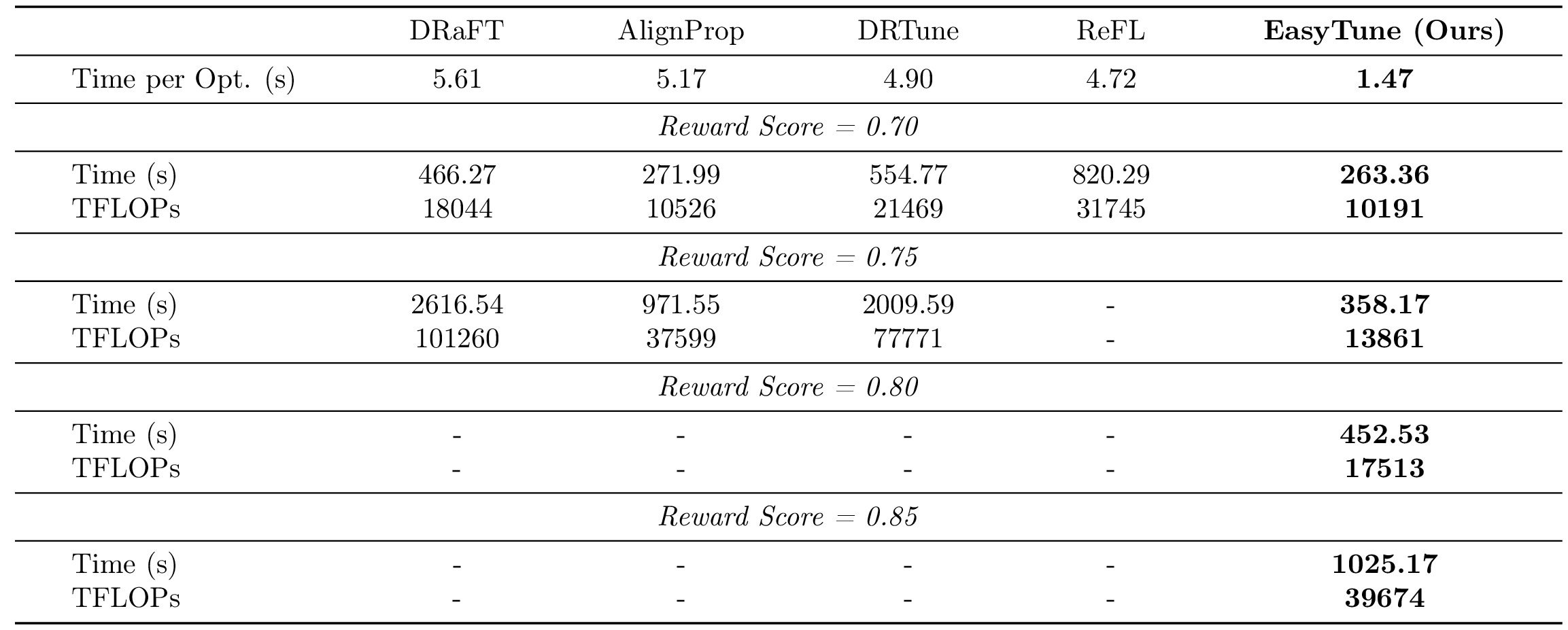
Table 5. Computational overhead comparison. We report the training time and TFLOPs required to reach different reward scores. Total time is measured in seconds on a single NVIDIA RTX A6000 GPU. "-" indicates the method could not reach that reward level within a reasonable training budget.
🎨 Visual Results
Figure 5. Visual results on HumanML3D dataset. "w/o EasyTune" refers to motions generated by the original MLD model, while "w/ EasyTune" indicates motions generated by MLD fine-tuned using EasyTune.
⚠️ Bad Case Analysis: Reward Hacking
Reward hacking is a known challenge in reinforcement learning, where continued optimization after convergence can degrade generation quality. This occurs when models over-fit to semantic alignment while neglecting realistic motion dynamics.
As illustrated in the videos below, models misinterpret prompts to over-fit specific actions. For example, the instruction to "lifts their right foot" may result in continuous, excessive lifting. Similarly, a sequence like "squats down, then stands up and moves forward" might be incorrectly generated as "squats down while moving forward."
Fortunately, this phenomenon can be effectively mitigated. Our method, combined with KL-divergence regularization, shows robust mitigation.
🎥 Motion Demos
Generated motion sequences comparing original vs. EasyTune fine-tuned models.
📚 BibTeX
@article{tan2025easytune,
title={EasyTune: Efficient Step-Aware Fine-Tuning for Diffusion-Based Motion Generation},
author={Tan, Xiaofeng and Weng, Wanjiang and Lei, Haodong and Wang, Hongsong},
journal={arXiv:2602.07967},
year={2025}
}